A Text Analysis Environment for Humanities Scholars
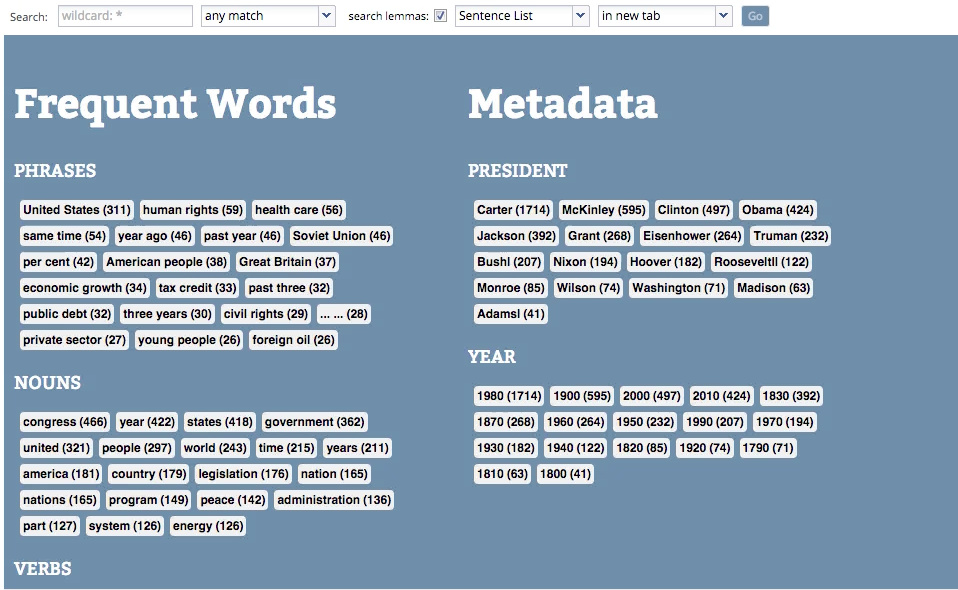
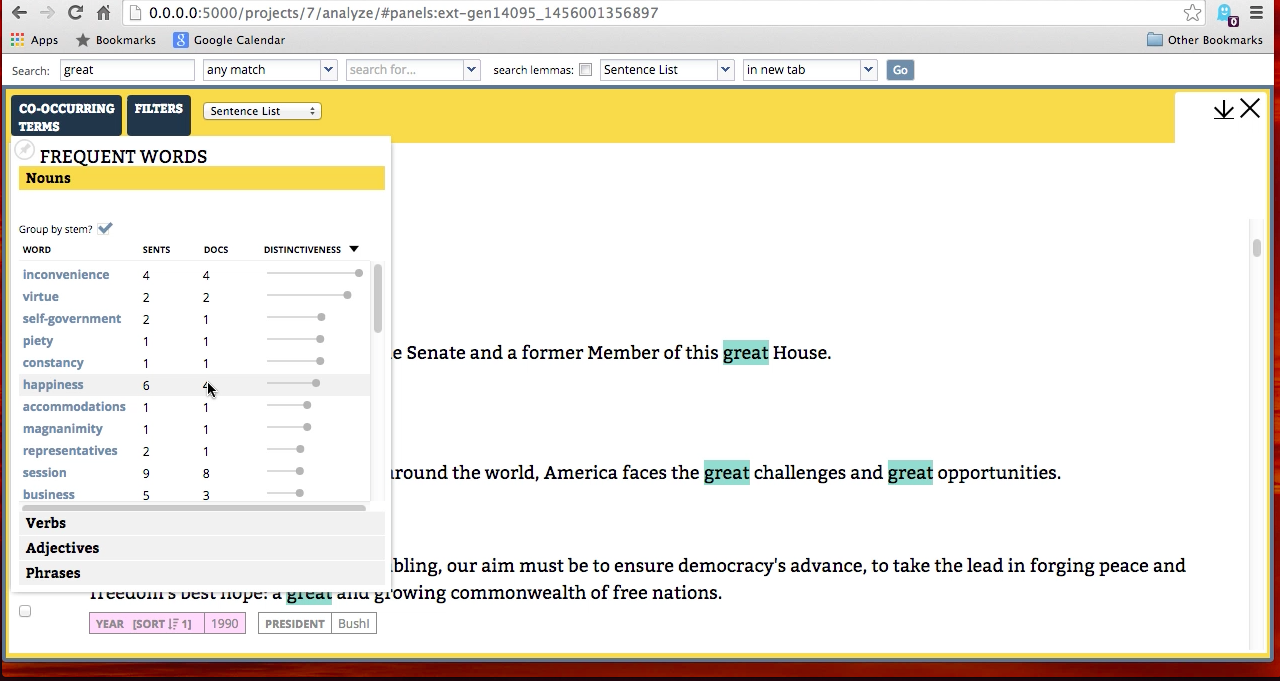
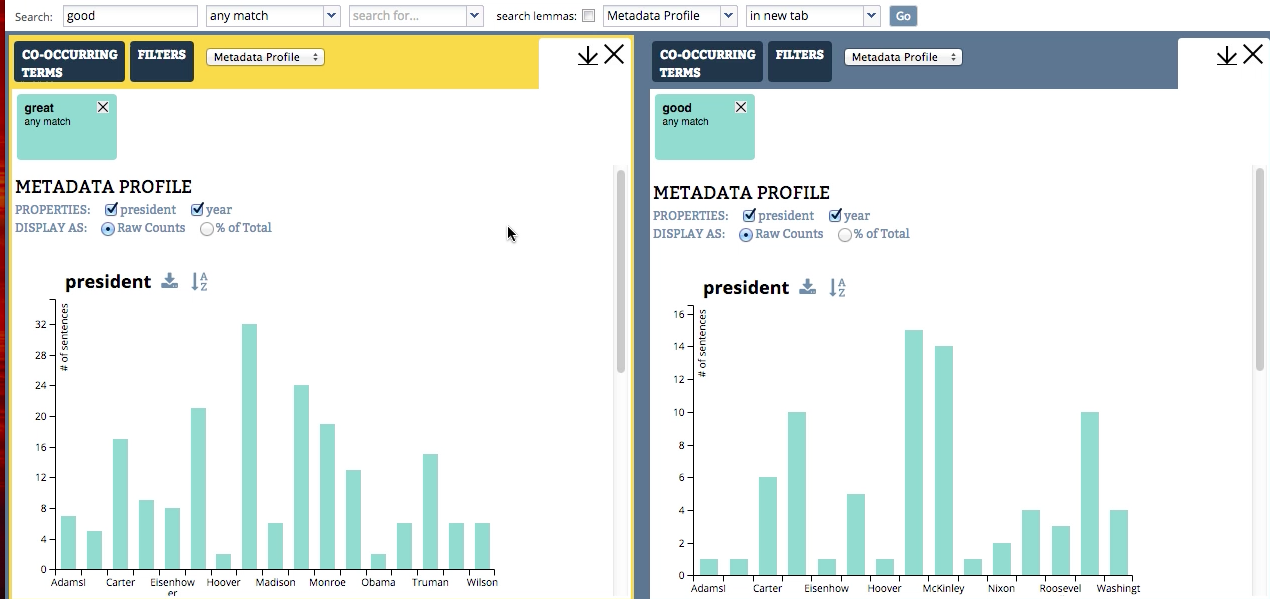
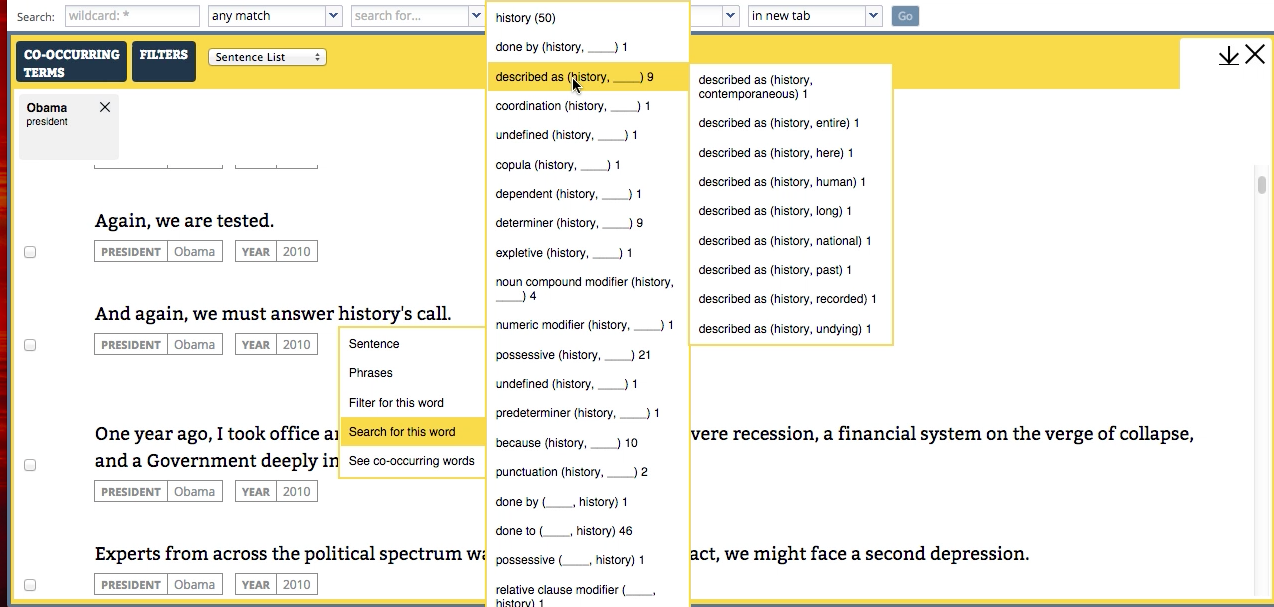
WordSeer is a text analysis environment that combines visualization, information retrieval, sensemaking and natural language processing to make the contents of text navigable, accessible, and useful.
WordSeer 4.0 has been Released!
We are pleased to announce the release of WordSeer 4.0.
Three new videos have been created to demonstrate the functionality of WordSeer 4.0.
Please use the code, and contribute enhancements and improvements on the github site.
WordSeer is supported by a grant from the National Endowment for the Humanities, Office of Digital Humanities, NEH HK-50011.