WordSeer 3.0 In Detail
We’re thrilled to announce the latest version of WordSeer!
After almost a year of improvements, WordSeer is now capable of much more than it ever was. You can now filter, get overviews of a collection, do side by side comparisons, open up multiple visualizations, drill down into what you see, and save and export your results. This post introduces the new features through a series of demonstration videos, analyzing 30 years of New York Times editorials about China and Japan. For easy skimming, it also explains the new features with text and screenshots, but with examples from Shakespeare plays — which we’ve analyzed before.
It’s not publicly available yet, because we’re still making improvements and we haven’t figured out how to handle the load, but we’re working on this.
Contents
Background
But first, some background. WordSeer is a web-based text analysis and sensemaking environment for humanists and social scientists. It’s a a research project at UC Berkeley’s Computer Science Division and School of Information.
Let’s unpack that:
Text Analysis and Sensemaking. Sensemaking is a bit of jargon computer scientists use to describe the complex, drawn-out, iterative process we engage in when we’re trying to process and understand information. All scholarly research is a form of sensemaking. We’re particularly interested in sensemaking with text data, because there aren’t too many tools out there for this. Sensemaking with text is more difficult than with other kinds of data, because the only really good way to get meaning out of text is to read it. Tables of numbers on the other hand, don’t need to be read in the same way to be meaningful. Numbers are therefore comparatively easier to condense, summarize, spot patterns with, and predict.
For humanists and social scientists. Literature scholars, historians, and many other kinds of humanist and social scientists (not to mention journalists and data analysts) need do text-based sensemaking very deeply every day. It’s a hard problem that needs a good solution.
WordSeer is a research project, funded by two successive NEH digital humanities grants. We’re computer scientists, and our goal is to figure out how to to make advanced computational technologies from the fields of information retrieval, data visualization, and computational linguistics work for scholars trying to deeply understand text.
Web-based. WordSeer is a program that runs in a web browser. In our case, the only browsers in which it works properly are Chrome and Safari (Firefox is currently breaking for mysterious reasons. see “research project” above). WordSeer’s main website is http://wordseer.berkeley.edu.
Previous Versions
Many of you already know WordSeer from its previous incarnations. You know we’ve been developing it through case studies with individual scholars, that we’ve already done a few demos and got a few results. But this is WordSeer’s biggest jump yet.
It began last spring, with a class of undergraduate Shakespeare students in Canada. In April of 2012, students in Michael Ullyot‘s “Hamlet in the Humanities Lab” at the University of Calgary had just finished putting WordSeer and four other web-based text analysis tools through their paces. The students had spent the first half of the class getting familiar with five tools (Voyant, Tapor, WordHoard, Monk and WordSeer). In the second half, they split into groups and each group analyzed a different act of Hamlet. Every week, they blogged about their experiences. At first, they talked about learning the tools — how they functioned, when they broke, what they seemed to be useful for. Later, they reported on using them to analyze text.
For the WordSeer project, those blog posts were a gold mine. We’d never had so many users, and we’d never had such detailed information about their experiences either. And these students weren’t just any users: they were motivated, skeptical, critical, and engaged. They used WordSeer over a significant amount of time, for pre-existing well-defined goals, and not just one-off “let’s see what this is about” sessions. At the end of the semester they had made around 180 posts.
It hadn’t even been a week before I was contemplating a significant change to WordSeer: the ability to isolate and group together sets of documents to analyze together. As a complete outsider, I’d failed to foresee something as simple as the students’ need to isolate just Hamlet for analysis. I quickly added it while they were still learning the tool, so that WordSeer wouldn’t fall behind, but then backed off for the rest of the semester, except for a minor bugfix or two. The result of the change was a post, a few videos, and a conference paper about comparative analyses in Shakespeare.
The semester following that, I conducted several interviews with history and English PhD students, as well as an online survey to flesh out other parts of my understanding. The result is WordSeer, version 3.
The New WordSeer
We redesigned WordSeer around the following common analysis needs that the old WordSeer just didn’t meet:
- Getting an overview of the contents of a collection or sub-collection
- Drilling down into a sub-collection of interest
- Narrowing down analyses by meaningful metadata, such as (in Shakespeare) a particular speaker, act, or scene.
- Exploring ideas for a new search or analysis based on the results of a current one
- Comparing two or more visualizations side-by-side or referring to multiple tools simultaneously
- Forming custom categories for analysis (e.g. male speakers, female speakers), and comparing analyses across those categories
- Investigating a group of words together
- Saving and exporting work
Now, we’re pleased to introduce WordSeer 3.0. Because it’s very interactive, and supports many continuous sequences of analysis, we thought the best way to do that was through a series of videos. But videos aren’t easy to skim, so the rest of this post explains the new features in regular blog format. If you’re still curious after the videos and reading this post, there’s also the WordSeer 3.0 Guide, but that’s more like an instruction manual for users.
A new collection: 5,000 New York Times editorials
In these videos, we’re analyzing a much larger text collection than we’ve ever done before. It’s every New York Times editorial about China or Japan published between 1980 and 2012. That’s about 5,000 editorials, each one about China or Japan or both. They were downloaded using Lexis Nexis, and filtered to just ‘China’ or ‘Japan’ using the subject categories available through that tool. This choice was motivated by the research interests of Chris Fan (@sea_fan) one of the scholars we’ve been collaborating with. He’s a PhD student in English at Berkeley and studies US-China relations. While taking our digital humanities course in the spring, he became interested in analyzing these articles computationally.
His work on American literature’s reactions to China’s rise draws upon a set of historical observations about the “rise of China” that are broadly accepted by historians and cultural historians. Literary scholars typically allow their claims to rest on observations made by field experts like historians and sociologists, or on their own inductive reasoning, but he wanted to verify some of those observations by gathering as much empirical evidence for them as possible.
Demo Videos
Although WordSeer is very cool (or so we think, at any rate) it is still kind of slow, so we’ve speeded these videos up to eliminate the 5 or 6 second waits that sometimes happen. Speed is very important to text analysis systems, and this is part of the reason we haven’t released it publicly yet. We’re working on it!
WordSeer Features
Overviews: what are the most frequent words? Who has the most lines?


The new system tries to expose as much of the content and diversity of the collection as soon as possible. Without having to type anything — or even know anything about the collection, a user is presented with four different kinds of overviews:
- An interactive Word Tree of the most frequent word in the collection — “good” (center)
- Overview-filters of the most frequent nouns, verbs, and adjectives (bottom)
- Overview-filters of the most frequent phrases (two or more words) (bottom left)
- A browsable list of categories extracted from the input XML. In the Shakespeare collection, these are Act, Scene, Play title, Speaker, and line number. (left)
At a glance, the user not only sees what the main categories and words are, but also sees how many sentences fall into each category.
As mentioned above, the previous WordSeer had no support for discovery or browsing. When you opened up the Shakespeare page, you couldn’t tell, for example, which the most prominent characters were, or what the most frequent words and phrases were. Also missing was the ability to navigate based on that kind of information. You couldn’t express filters, like “all sentences spoken by Gertrude” or “everything from Act 3 of Romeo and Juliet”, only searches.
That is why all overviews in WordSeer double as navigable filters. For example, if I click on “Hamlet” under the “speaker” list in the categories on the left hand side of the figure above, WordSeer will filter my view to just the sentences in which the “speaker” is “Hamlet”.

The result is still an overview, but of a smaller set of sentences: just those in speeches by Hamlet. All the details change: the Word Tree (center) changes to show the contexts surrounding the most frequent word in his speeches, and the lists of frequent words (bottom) and phrases (bottom left) also change to reflect the content of Hamlet’s speeches:

The above example deal with categorical metadata. But what data types that are more naturally expressed as continuous ranges, such as time? For these data types, the metadata pane shows a different type of overview-filter, a distribution chart. In our Shakespeare collection, the only numerical data type we have is “line” for the line number within the scene. This is what the overview-filter looks like:

If I want to look at just lines in a particular range, I can drag the handles and click the “filter” button:

In other collections, these sliders might be used to select date ranges or other more meaningful spans.
Getting a sense of the contents of your data: discovering ‘good night’
The overviews I’ve described so far give you a sense of how your metadata attributes are distributed, but what if your collection doesn’t have any built-in categories like ‘speaker’ an ‘Act’? How do you get a sense of its contents? One task that came up over and over again was this one: getting a sense of the contents of some collection of text.
In WordSeer, that’s why we have overviews of frequent words and phrases, and these overviews change to reflect the searches and filters you’ve applied.
Frequent Phrases
One way to get a sense of the contents of a text collection is to look at frequent phrases. In WordSeer, “phrases” are sequences of two or more words. Every panel in WordSeer shows you an overview of the most frequent phrases in whatever intersection of searches and filters you’ve selected . For example, if we zoom in on the panel showing the list of sentences in Hamlet, we see the most frequent phrases in just Hamlet:

This frequent phrases overview doubles as a filter. For example, if you want to see all 13 occurrences of “good night” in Hamlet, you can click the table row for “good night”, producing this:

Frequent Words
That’s not the only kind of overview you get. Just like we can discover the most frequent phrases, we can discover the most frequent nouns, verbs, and adjectives. WordSeer uses a computational linguistics technology called part-of-speech tagging to automatically categorize words into their parts of speech. For example, here are the most frequent nouns, verbs, and adjectives in Hamlet:

There is an option: “group by stem”. A stem is a common root from which different word forms are derived. For example, enabling this option would group together “read”, “reading”, and “reads” under the single label “read”, and show the added-up count for all of them. Just like the list of phrases, these word lists double as filters. For example, clicking on the word “lord” in the list above would further filter the “Hamlet” sentences to just those containing “lord”.
Video 1 demonstrates these overview and filtering features on the China & Japan editorials, showing how, by successively using overviews and filters (and with absolutely no prior knowledge of the collection), we can discover that, in the 1980s, there was a controversy over Japan’s take on whaling for research.
Search
The most basic component of any text analysis system is search, and WordSeer supports that. It also has a way to discover grammatical relationships between words, and we’ll talk about that too.

WordSeer has a pretty complicated search box, but for simple searches, you can ignore most of it.

To perform a keyword search in WordSeer, type words into the search box, and leave the grammatical relation set to ‘anywhere in the text’. It will show you a list of search results, and you can click anywhere. Video 2 demonstrates this feature on the China and Japan editorials.
Grammatical Search: how are facial features described?
Sometimes keyword search isn’t enough, often, what we’re really after are questions like ‘What does X do?” and “How is X described”. These aren’t keyword searches, but questions about the relationships between words — what verbs apply to X, what adjectives?
WordSeer’s other search mode allows you to search over exactly these types of grammatical relationships. These relationships are things like “verb subject”, “verb object”, “adjective modifer”, etc. Grammatical search allows you to ask questions like, “what are all the adjectives that apply to the word ‘man'”, and “what are all the verbs that ‘Hamlet’ is the agent of”?
The full list of grammatical relationships supported by WordSeer is described in detail here, in the Stanford Dependencies Manual. It explains all the different kinds of relationships available in WordSeer and gives examples of them in sentences.
Grammatical searches are more complex because there are three pieces of information in a grammatical relationship.
-
The type of relationship
-
the first word in the relationship
-
and the second word in the relationship.
Why aren’t 2 and 3 interchangeable? Consider the two sentences “Look at the poster display, it’s really nice”, and “Look at the display poster, it’s really nice”. In both cases, there’s a noun compound relationship between “poster” and “display”. However different word orders give the compounds slightly different meanings. In the “poster display” is a display of posters which is really nice, in the second “display poster” is a poster for display, and the poster is really nice. Computational linguistics technology represents the two relationships as noun_compound(display, poster) and noun_compound(poster, display).
Performing a Grammatical Search
You can activate grammatical search mode using the drop-down menu in the top search bar. Selecting any relationship other than “anywhere in the text” will perform a grammatical search with that relationship. Another search box will appear to the right of the relations menu, so you can specify both words.

The Grammatical Search Bar Charts visualization was developed specifically for grammatical search queries. It’s like a list of search results, except augmented with bar charts of how many words match the grammatical relationship. Below, the figure shows how this visual can, be used to investigate descriptions of facial attributes in Shakespeare:

searching for the “face, eyes, hair [described as] _______” with the Grammatical Search Bar Charts visualization.
The results of this search are shown below:

The bar charts show how often the each of the words appear in a “described as” relationship, as well as the words that describe them. Above, the chart shows that “eyes” is the most commonly described feature, at 83 times. The list of matching sentences is below the chart, with the matching words highlighted. The charts are also interactive. Clicking on a word filters the list of sentences to match that word, as shown below:

Visualizations and search results are often just a starting point. We often do multiple initial searches, and only drill down after we see something interesting, or have gotten a sense of the contents of the collection. But in the old WordSeer, there was no good way to follow up and drill down. That’s why one of the most powerful new ways to get around WordSeer is the Word Menu. When you see something interesting in a visualization, the word menu gives you a way to follow up on that thought by creating a new visualization, adding something to a group, or exploring related ideas.
Words appear in a lot of different places in WordSeer — lists of frequent words, lists of nearby words, in document views, in sentence popups, and in the list of sentences. If a word turns blue when you hover over it, right-clicking on it will make a word menu:

The search options in the word menu allow you to create a new visualization around that word. For example, clicking on ‘Search’ in the menu above will open up a search for the word ‘father’ in a new panel.
Discovering the grammatical neighborhoods of words: how are fathers described?
One of the most common questions we encountered about words was ‘how is this word used?’ That’s why the word menu includes the ability to explore the grammatical neighborhood of a word. What’s a grammatical neighborhood? It’s a term I made up to stand for the way a word interacts with other words. You can see the grammatical neighborhood of a word by clicking on it (to open the Word Menu) and exploring the search options.
For example, the Word Menu for “father” shows the different ways in which “father” is used, and the number of times each one appears in the collection. Suppose we look at the “adjectival modifier” search option. This shows us the different adjectives that apply to the word ‘father’. Examining it, we discover that fathers in shakespeare are “good”, “dear”, “noble”, “ghostly”, “royal” and “sweet”:
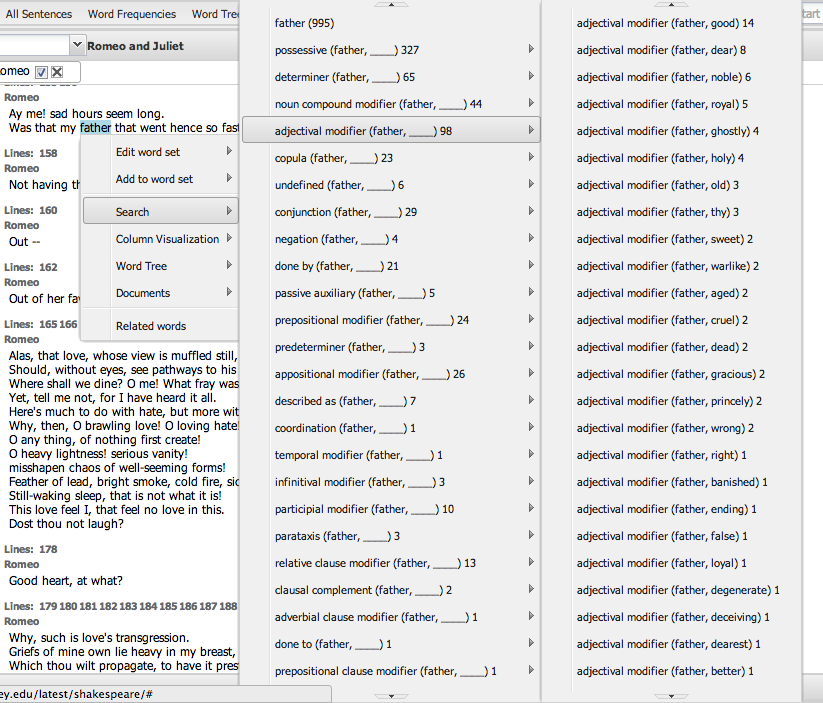
Clicking on any of these options does a grammatical search for that relationship, and brings up the search results in a new panel alongside.
Video 5 demonstrates this on the China & Japan editorials, showing what we discover when we explore the grammatical neighborhood of the word ‘China’.
Related Words: what gets said around ‘son’?
Another way WordSeer lets you get a sense of how a word is used is through the ‘Related Words’ option. This shows you all the different words that co-occur in the same sentences as a given word.
This option pops up a window showing nouns, verbs, and adjectives that frequently occur along with that word. These words are sensitive to the searches or filters we’ve applied. For example, if we had previously searched for “father” and then wanted to investigate the word “son”, then the related words would only compute co-occurring words for “son” in the context “father”:
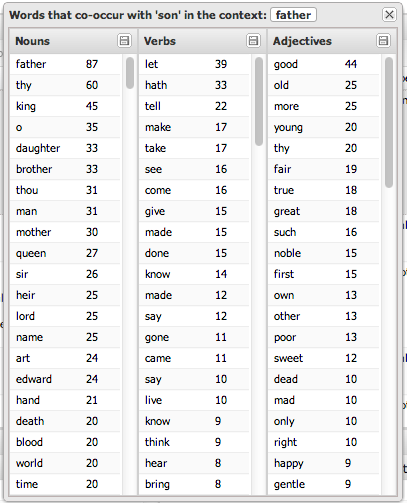
Of course, this list of co-occurring words is just that, a list of words, meaning that clicking on any of them would again bring up a word menu. Except, because these are co-occurring words, these word menus are special: they have an extra option, ‘see co-occurrences’.
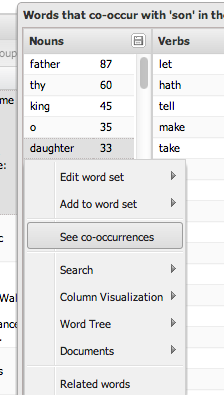
Clicking on the “see co-occurrences” button above would bring up just those sentences where “son”, and “daughter” co-occur in a separate panel. Video 6 demonstrates this for the China & Japan editorials.
Side-By-Side Comparisons: love in the comedies and tragedies
In the old WordSeer, side by side comparisons were a pain — yet the students in “Hamlet in the Humanities Lab” needed to do them all the time! You can see what I mean in this video, in which I compare the word “love” in the comedies and tragedies. You had to open up a new browser window, navigate to WordSeer, then type in the other search, and then switch between the two browsers.
This is why the new WordSeer has been redesigned to work somewhat like a computer desktop environment — it can display multiple “panels”, each with different information.
For example, here I am repeating a previous analysis from WordSeer 2 — comparing “love” in the comedies and tragedies. two Word Tree for “love” side by side: over the comedies in the left panel, and over the tragedies in the right panel:
 and the tragedies (right)")
Video 3 demonstrates how to open up multiple panels, and shows how we can use this new feature to great effect in the China & Japan editorials to compare the language around the word ‘China’ across the 80s, 90s, and 2000s.
Analyses Across Categories: supernatural words across the different acts of Hamlet
A common kind of analysis we found, not just in the blog posts but in our interviews as well, was comparing categories of data along some dimension. As a simple example, in Shakespeare, students would often pose questions like this, “How does the theme of the supernatural in Act 1 differ from Act 2”, or “How do the different characters’ levels of involvement change throughout the play?”.
These questions involve comparing two or more pre-existing categories: Act, Scene, Speaker, along some dimension: “theme of the supernatural”, “involvement”, etc.
The old WordSeer simply had no way to express such an analysis goal. You could search. That was it. If it wasn’t a search, you were out of luck.
That’s why we developed the “Word Frequencies” tool for the new WordSeer. It’s got a cryptic name (I’m not very good at names), but look how naturally it expresses these types of questions.
For example, I can search for the terms “ghost, spirit, heaven, hell” — an approximation to the “supernatural theme”, and see how the frequency of those words varies across all the different categories within my data, including Act:

These graphs are interactive, I can click, for example, on just ‘Act 3’, and that shows me which characters talk about ‘heaven’, ‘hell’, ‘ghost’, and ‘spirit’ the most:

Video 4 demonstrates this feature on the China & Japan editorials, by showing how we can use it to look at trends of words like ‘economy’ and ‘world’ over time, and to compare the trends for the two different countries.
Custom units of analysis
Pre-existing divisions (such as Act, Scene, Speaker, etc.) are useful, but they’re almost always not enough. As a scholar’s understanding of a body of text grows, he or she collects, categorizes and re-categorizes quotes, sentences, and documents into new categories.
For example, consider the question, “How does the treatment of love in Shakespeare vary between the comedies and tragedies”? Here, “comedies” and “tragedies” are units of analysis that don’t come pre-defined in our collection (but maybe they should?).
A better example of such a question is “What are are the different characteristics of speeches by male and female speakers?” Here, our units of analysis are “speeches by male speakers” and “speeches by female speakers” — we don’t have those as pre-defined categories either.
And yet another is, “How do concepts of emotion correlate with mentions of people in power — how often do emotions like “anger”, “sadness”, “joy”, “hate” correlate with different kinds of people in power? This is more complex. We want to look at “the sentences mentioning different types of people in power” and correlate them with “sentences mentioning different types of emotion”.
Here I’ll show how WordSeer’s Document Sets, Sentence Sets, and Word Sets features can help conduct exactly these types of analyses.
Sets aren’t just for comparison — once you make a set, it persists, you don’t lose it. You can use them to collect interesting things to look at, or to make conceptual groupings for your own understanding.
Document Sets: ‘in love’ in the comedies and tragedies
Document sets are most useful when you’re looking at gathering certain types of documents together. You make document sets by searching and filtering in the document browser (that’s a link to the guide entry). To make a document set, just select some documents, and click “Add to Group”.
For example, If you wanted to follow up on the question of “How does the treatment of love vary between the comedies and tragedies”, we could do that in the following way. First, collect all the comedies:

Then, add them to a group by clicking the “Add to group” button at the top, and typing in what we wanted to call it:

We’d name the new group “comedies”, and hitting enter would create a new group: “comedies”. We can do the same for Tragedies, and the Document Sets overview now shows two sets, “comedies” and “tragedies”

We can now use these sets as filters, because they appear in the metadata overview:

So, now if we wanted examine the treatment of “love” across the two sets of documents, we could do a word frequencies comparison. The word frequencies chart automatically uses the new document set categories.

Sentence Sets: Comparing male and female speakers’s participation patterns
You can put sentences into sets from the List of Search Results and Grammatical Search Bar Charts views. Click the checkboxes next to the sentences you want, and then add them to the set. For example, let’s collect speeches by female speakers in “The Merchant of Venice” into a sentence set. First, narrow down the list of sentences to just that play.

Use the auto-suggest box to quickly select to “Merchant of Venice”. Then we can use the category filters to drill down into the sentences spoken by each female character, select them, and then add them to a sentence set.
Here, I’ve just finished adding the 240 sentences spoken by Portia to the set, and I’m about to add 50 by Nerissa:

After adding all the women’s sentences, I get 338 sentences. After doing the same for the men, and ignoring characters with less than 5 sentences, I get:

Now I can begin comparing them. I open up two panes, and look at the word frequencies across the acts for the two sets:

The lists of frequent words (bottom of each panel) in the two panels are all slightly different from each other, and the characters’ patterns of involvement in the play are also very different.
Word Sets: anger and joy expressed by powerful beings
One pattern of analysis that came up over and over again was investigating a group of words together. Both undergraduate students in the shakespeare class and the PhD students we interviewed would describe collecting or identifying a group of words of interest, and then analyzing them further in some way. The further analyses differed: it could be searching for occurrences, trying to find patterns of co-occurrence or distribution, or something else, but this basic pattern: collect a group of words, then analyze it, was the same.
In WordSeer, we support this kind of analysis using Word Sets. These are are just collections of words. However, like document sets and sentences sets, they are units of analysis that have an independent existent. They act as filters, matching all the sentences that contain the words in the set, and can be used as search terms in the search box. Instead of typing in a long list of words, you can just use the word set instead:

Word Sets with the Word Menu
As we saw in the word menu section, clicking or right-clicking on a word almost anywhere in WordSeer opens up the Word Menu. We saw how the word menu is a jumping-off point for analysis, but it’s also designed as a way to quickly collect words of interest into groups. The word menu has options to either add the word to a word set (you can add it to a new one if you don’t have existing ones) and to edit existing word sets:

If you make a new set, it’ll automatically be named after the word, and you can add more words to it using the word menu. Here, let me add ‘king’ to the ‘lord’ word set I just made:

Of course, it’s extremely cumbersome to click and add words individually if you already know which ones you want to add. You can therefore edit word sets directly, and type words in. Use the ‘Edit word set’ option to bring up that window:

This brings up a little window that you can edit, and you can click on the title bar to rename it.

Word Sets with the Sets Pane
You can also make and manage your Word Sets with the “Word Sets” overview:

Clicking “New” creates a new set, and “Delete” deletes the selected set. Double click to open the word set up in a window, or to rename it. Here, I’m creating a new set and naming it “god/supernatural”:

In this set, I put “god, almighty, heaven, and spirit”, so I can compare how some emotion-related words co-occur with the two categories.
For this, I simply do two searches in the word frequency graph and compare the split across categories. As expected, the comedies have more happiness and the tragedies have more anger, but the comparison between royals and supernaturals is interesting:
 and happiness-related words (orange) across the comedies and tragedies, and the 'royals' and 'supernaturals' words")
It appears, in fact that the “royals” words are much less associated with the happy search (orange) than the “god/supernatural” words. Only 0.61% of the royal sentences have “happy” words, whereas twice as many (proportionally speaking) of the “god/supernatural” sentences have “happy” words.
Saving and Exporting Work
WordSeer isn’t a do-all system. It lacks even rudimentary note-taking capabilities, and it’s really more of a hypothesis-generation and evidence gathering tool than a hypothesis-testing one. That’s why you can export almost all the data you see — from the lists of frequent words, to the graphs and figures, to the lists of sentences, to the distributions of categories out of the tool, so that you can include it into your other work, or do more sophisticated statistics on it.
Every single WordSeer data display has a tiny save button on its top left:

For image-based visualizations, such as the Grammatical Search Bar Charts, Word Trees, and Word Frequencies, click on the save button at the top of the panel to generate download links to each of the visualizations as an image:

If you want to save the image in a filtered state, just click the save button after performing your operations — the images generated always reflect the current state of the chart.
History
Finally, the last thing we created is a persistent History store on your computer, which may not seem like such a big deal, but just makes things more convenient. Because WordSeer is an application that runs inside your web browser, it’s common to leave and return later, with a new session. It’s also easy to accidentally close the page. But with the History module, when you open it up again, your history will be available to you from the pane on the left. Just click a row to open up the panel again. Your history won’t be available if you use a different computer or a different username though.
